
Let's transfer a models learnings
"Transfer learning is like bringing a friend to a new party. Your friend already knows some of the people there and can introduce you, saving you the awkwardness of having to make new connections from scratch. That's what best friends should do right !! ..

Breaking Barriers: Democratizing Access to Vector Databases
Large language models (LLMs) and AI-related technologies are on everyone’s lips. Vector databases, the critical infrastructure for LLMs and AI applications, have gained widespread attention from a broader user base, expanding from algorithm engineers to include application and backend developers.
Simple analogy before we begin :
"Transfer learning is like bringing a friend to a new party. Your friend already knows some of the people there and can introduce you, saving you the awkwardness of having to make new connections from scratch. That's what best friends should do right !! .. Here is transfer learning.
Contents covered :
1. Introduction to Transfer learning
2. Pre-training to Fine-tuning journey
3. Application areas of transfer learning
4. Design a transfer model
5. Closing points
Introduction to Transfer learning
Transfer learning is a popular Deep learning technique that reuses previously learnt features from a model as a starting point for new task. This approach reduces the burn complexity of training a neural network right from scratch.
Brief History : One of the earliest examples of transfer learning can be traced back to the 1990s, when researchers in natural language processing used pre-trained language models to improve the performance of new tasks, such as language translation and text classification.
However, it was the emergence of deep learning in the mid-2010s that really popularised this approach in machine learning. In 2012, the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) was held, which marked a turning point in computer vision research and led to the development of many pre-trained models that have been used as starting points for a variety of image recognition tasks. Since then, transfer learning has become a key technique in many areas of machine learning, including computer vision, natural language processing, and speech recognition.
Pre-training to Fine-tuning journey
In transfer learning, a model is first trained on a source task to learn relevant features from the input data. These learned features are then transferred and reused to train a new model on a different target task. Typically, the source model is fine-tuned on the target task to further improve its performance.
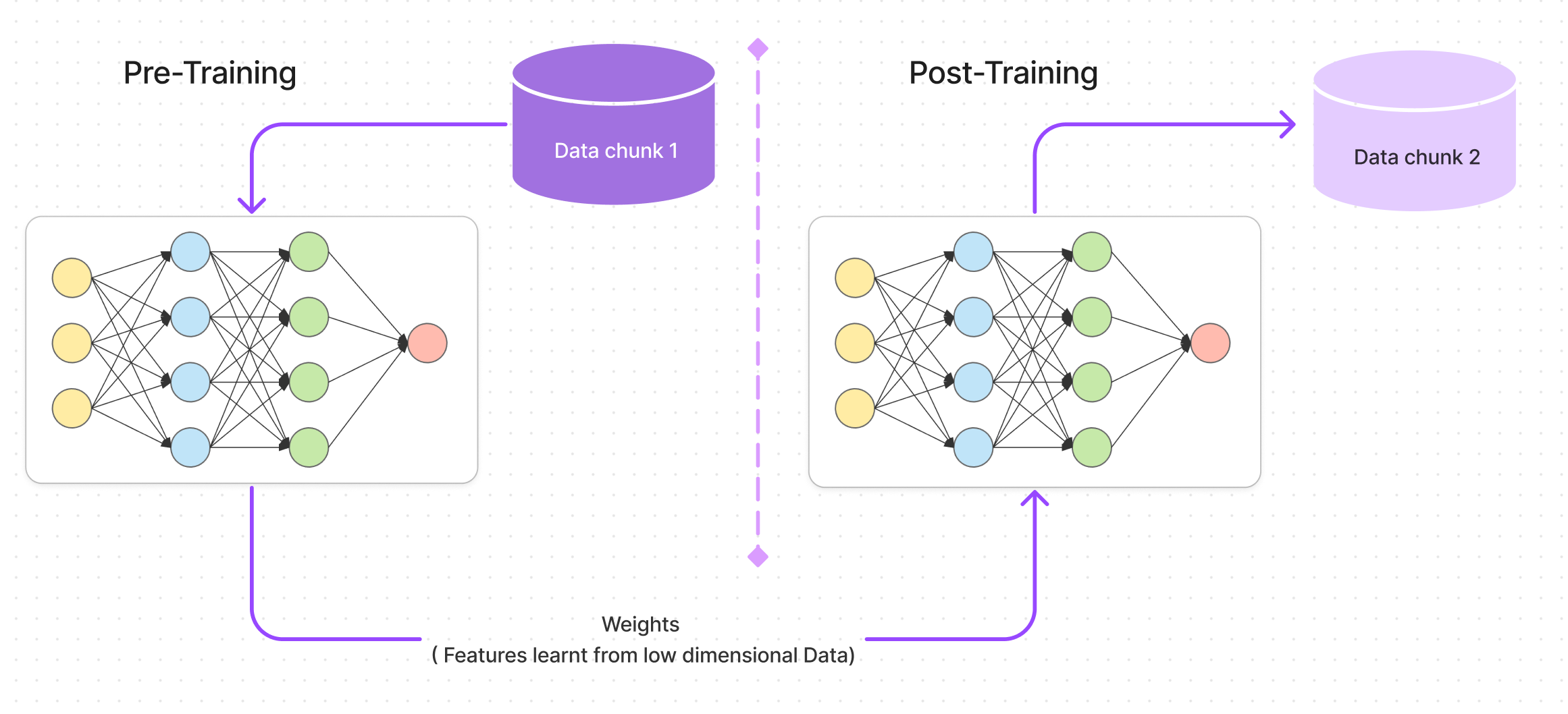
This journey can be condensed down into 5 major steps as follows :
- Selecting a pre-trained model: The first step in transfer learning is to select a pre-trained model that has already been trained on a large dataset. The pre-trained model should be chosen based on its architecture and the similarity of its training task to the new task at hand.
- Removing the top layers: Once a pre-trained model has been selected, the top layers are typically removed. The top layers of the pre-trained model are usually responsible for the final classification task, and they are not useful for the new task at hand. By removing the top layers, we can extract the features learned by the pre-trained model and use them as inputs to a new model.
- Adding new layers: After removing the top layers, we can add new layers to the pre-trained model. The new layers are typically specific to the new task and are responsible for the final classification or regression. The number and type of new layers will depend on the complexity of the new task and the amount of available data.
- Freezing the pre-trained layers: The next step is to freeze the weights of the pre-trained layers. This means that we prevent the pre-trained layers from being updated during the training process. Freezing the pre-trained layers allows us to use the pre-trained weights as a fixed feature extractor and prevents the gradients from back propagating through these layers and potentially destroying the learned features.
- Training the new model: Finally, we train the new model using the new layers and the frozen pre-trained layers. We typically train the new layers first, using a small learning rate to prevent destroying the pre-trained weights, and then fine-tune the entire model with a larger learning rate to adapt to the new task. The number of epochs and other training parameters will depend on the new task and the available data.
Application areas of transfer learning
As the trend goes, transfer learning can be combined with other machine learning techniques, such as data augmentation, meta-learning, and active learning, to improve the performance of models further. Here are some trending domains where transfer learning is extensively used:
- 🎡 Multi-task learning: In multi-task learning, a single model is trained to perform multiple related tasks. Transfer learning can be used to initialise the model and fine-tune it for each task.
- 🙈 Unsupervised pre-training: Unsupervised pre-training is the process of training a model on a large amount of unlabelled data before fine-tuning it on a smaller labeled dataset. This can improve the model's performance and reduce the amount of labeled data required for fine-tuning.
- 🥊 Domain adaptation: Domain adaptation is the process of adapting a model trained on one domain to another domain. For example, a model trained on images of cats and dogs could be adapted to recognise images of lions and tigers.
- 🔫 Few-shot learning: Few-shot learning is the process of training a model to recognise new classes of objects with only a few examples. Transfer learning can be used to initialise the model and adapt it to the new classes.
- 🪃 Continual learning: Continual learning is the process of training a model to learn new tasks over time without forgetting what it has already learned. Transfer learning can be used to initialise the model for each new task.
Design a transfer model
To make the understanding easy here is an implementation of a transfer model train
Let's conclude
key take aways
- Transfer learning can save loads of computation by designing ensemble models that learn and transfer weights to the successor model.
- Both the old and new classifier take in and give out same dimensional input and output, any change required in new model can result is training previous models as well.
- Multi tasking learning, Unsupervised pertaining , Domain Adaptation , few-shot learning and continual learning are some of the few fields to explore as a transfer learning field.
"In conclusion, transfer learning is like having a friend who's already an expert in a topic you're trying to learn. They can give you a head start ☄️ and help you avoid common mistakes. And just like how you wouldn't want to rely on your friend forever, you also don't want to rely on pre-trained models forever. So, take what you learn from them and apply it to new challenges.
Who knows, maybe one day you'll be the friend giving others a head start. And if not, you can always buy your friend a ☕️ as a thank you for all the help."